#RGPD : Les "dark patterns", ou comment s'asseoir sur le Règlement
Vous l’avez sûrement remarqué, que ce soit pour exprimer vos préférences vis-à-vis des cookies sur d’innombrables sites web, ou au travers de diverses applications mobiles, réseaux sociaux… Quand bien même on vous demande de « revoir vos paramètres », il y a des dizaines (voire des centaines dans certains cas, coucou Yahoo) de cases à décocher, alors que c’est pénible et que c’est supposé être un véritable « opt-in » (à savoir, une inscription qui nécessite une véritable action positive de votre part, comme un clic dans une case).
Du côté des gros affamés de données (Google, Facebook), c’est la même, en plus chafouin. Tout est pensé pour que la collecte de données personnelles puisse continuer à avoir lieu. Le tout bien caché derrière un petit assistant en 4-5 écrans qui vous explique que olala le RGPD on l’a bien pris en compte. Et quand vous creusez… C’est la cata.
Toutes ces techniques, on les appelle les « dark patterns » (eux-même partie intégrante de la « captologie »), et l’équivalent norvégien de l’UFC Que Choisir (le CCN, pour Consumer Council of Norway) les a documentées, fort précisément (mais en anglais). Du coup, je vais vous résumer leur rapport, qui se concentrait sur 3 acteurs : Facebook, Google, et Microsoft (au travers de Windows 10).

Vous le savez tous si vous traînez un peu ici ou si la thématique « données personnelles » vous intéresse : dans le « digital », la valeur, c’est souvent la donnée (et tout ce qu’on peut en tirer, en analyse, en revente…). « Si c’est gratuit, c’est vous le produit » ! En fonction des données que vous fournissez, pas toujours consciemment d’ailleurs, on peut notamment mieux cibler les publicités, et donc les vendre plus cher aux annonceurs. Un profil plus rempli, avec parfois des milliers de paramètres différents, ça vaut un peu de brouzoufs, et ça, les requins de la donnée ne l’oublient pas. Et donc, le RGPD, ça les contrarie : redonner du pouvoir aux utilisateurs, devoir leur expliquer ce qu’on collecte et pourquoi, avec qui on partage ça, et en plus leur laisser la possibilité de dire qu’ils sont pas d’accord ? Mais on marche sur la tête.
Le scandale Cambridge Analytica nous a montré, s’il fallait encore s’en convaincre, que des données pourtant parfois sensibles pouvaient être détournées de leur usage initial, pour des tâches aussi nobles que… influencer le vote des gens.
La « fuite » Grindr ? Top aussi : retrouver des informations comme son « statut VIH » sur le net, ça a de quoi faire flipper. Et des bricoles comme ça, on en voit passer toutes les semaines. Si c’est pas tous les jours.
On comprendra aisément qu’une entreprise qui base son business model sur le traitement et la vente de données personnelles va miser gros sur la collecte de ces données, qui doit être la plus efficace et large possible : plus il y en a et plus elles sont exactes, plus on en fait des profils précis qu’on peut monnayer cher. Pourquoi pensez vous que les CGU Facebook vous imposent de garder vos données à jour, et vous interdisent l’emploi de pseudonymes ?
Idéalement, si j’étais Tronchelivre Facebook, je m’arrangerais pour vous en révéler le moins possible sur cette collecte. Histoire de ne pas éveiller les soupçons. De fait, cela va créer une relation totalement asymétrique entre l’utilisateur (vous) et le fournisseur de service (Facebook, Google, tout ça). Au seul bénéfice dudit fournisseur.
Et l’une des façons de maximiser cette collecte, c’est d’utiliser les fameux « dark patterns » dont nous allons parler : des choix d’interface, d’options, de vocabulaire, faits volontairement pour tromper, leurrer l’utilisateur. On entretient le flou, on complexifie l’accès aux options vous permettant de sauvegarder un petit peu de vie privée.
Des choix douteux mais réfléchis
Dans le cas « normal » (qu’on attend, en tout cas), le design d’une application est centré sur l’utilisateur : faciliter l’accès aux éléments importants, comment répondre à son besoin le plus efficacement possible.
Dans les cas qui nous occupent aujourd’hui, on n’est pas vraiment dans la même démarche. On va y ajouter un soupçon (un bon gros, quand même) d’analyse comportementale et de psychologie. L’idée : exploiter des biais cognitifs et psychologiques pour amener l’utilisateur à faire des choix qui « arrangent » l’éditeur, sans soulever trop d’opposition. L’utilisateur va, à cause des biais exploités, faire des choix non rationnels, sans même en être conscient.
Un exemple : en général, un individu va avoir tendance à préférer une récompense immédiate mais sans grande valeur, plutôt qu’une récompense de grande valeur mais plus longue à obtenir.
Un autre biais très souvent exploité est le « biais de confirmation » : on se tourne plus facilement vers des contenus qui correspondent à nos idées (notamment pré-conçues) que vers des contenus qui bousculent nos « valeurs ». Un anti-vaccin, par exemple, va directement accorder plus de confiance à un article qui tape sur les vaccins (sans même l’avoir lu, juste d’après le titre ou le résumé) qu’à un autre qui irait à l’encontre de sa pensée (ici pré-conçue, puisque non-étayée scientifiquement). Parce que ça le conforte dans son opinion, parce que ça le rassure. Et on peut facilement exploiter ce genre de biais.
Donc, les biais. Un concepteur d’interface, s’il les connaît et les prend en compte, peut tout à fait pousser l’utilisateur à effectuer un choix plutôt qu’un autre. Et l’interface a nettement plus d’importance que les mots employés.
Bref : tromper volontairement l’utilisateur en mettant en œuvre ce genre de techniques, qui vont finalement à l’encontre de l’intérêt de l’utilisateur, c’est ça, un « dark pattern ».
L’utilisation de dark patterns pose notamment un souci éthique. Déjà que la relation utilisateur/fournisseur est déséquilibrée, en plus on vient faire pencher la balance avec des éléments trompeurs. D’autant plus grave quand l’utilisateur a placé sa confiance dans le fournisseur de service : lui, il sait sûrement mieux que moi ce qui est bien pour utiliser le service de façon optimale. Alors quand il vous dit que tel réglage (pourtant plus respectueux de votre vie privée) risque d’affecter assez fortement votre expérience sur le service concerné… le doute s’installe. Puis arrive l’hérésie suprême : la rémunération même pas dissimulée de vos données personnelles.

Et le RGPD dans tout ça ?
Pour l’Union Européenne, le droit à la vie privée et la protection des données à caractère personnel sont fondamentaux. En conséquence, l’UE a revu l’ancienne directive et a adopté le Règlement Général sur la Protection des Données, entré en application ce 25 mai 2018 en renforçant les droit des individus et les obligations des entreprises utilisant les données personnelles. Ce Règlement s’applique dès lors qu’un service est fourni à un utilisateur se trouvant sur le sol européen. On ne va pas refaire le tour du propriétaire en ce qui concerne le RGPD, je l’ai déjà fait en long, en large et en travers. Retenons simplement que parmi ce qu’introduit/renforce le règlement, on trouve deux notions potentiellement liées aux « dark patterns » : privacy by design, et privacy by default.
Selon ce dernier principe, lorsque Facebook ou Google vous présentent leur nouvelle politique de confidentialité, ils devraient pré-cocher l’option la plus protectrice pour vos données. Il se trouve que c’est également celle qui leur rapporte le moins et les contraint le plus en termes d’utilisation effective des données qu’ils collectent pour pouvoir rendre le service pour lequel ils existent. Toutes les données « bonus » dont ils n’ont pas strictement besoin pour vous rendre le service vendu (gratuit, c’est une illusion) mais qu’ils demandent à traiter quand même, requièrent pour être traitées légalement votre consentement libre et éclairé. Éclairé, cela sous-entend qu’une information sur leur utilisation vous a été fournie dans tes termes compréhensibles. Libre, parce que puisque ces données ne sont pas strictement nécessaires à la fourniture du service, vous êtes en droit de ne pas accepter de les fournir. On ne peut pas (j’insiste) vous interdire l’accès au service parce que vous refusez de fournir des données personnelles non-nécessaires à la fourniture dudit service.
Avant le RGPD, la plupart de ces services demandaient un consentement générique. Vous consentez à ce qu’on utilise vos données, point.
Aujourd’hui, non seulement l’éditeur doit préciser ce qu’il fait de vos données, mais en plus le consentement doit être distinct/spécifique à chaque finalité. Je peux consentir à ce que Facebook utilise mon adresse mail pour m’envoyer des notifications. Mais je peux ne pas vouloir qu’il la transfère à Midas pour me spammer de promos sur la révision d’un véhicule.
Ce qui explique la terachiée de mails que vous avez reçus fin-mai début-juin, pour renouveler/donner/retirer votre consentement.

Concrètement, qui a fait quoi ?
Déjà, il est important de souligner que les 3 exemples pris par le Consumer Council of Norway ont un rapport différent aux données. Google et Facebook ont un business model basé sur la monétisation des données, ce qui leur permet de fournir un service « gratuitement » aux utilisateurs. Microsoft, pour sa part, se repose moins sur la monétisation pour survivre.
Le CCN a basé son analyse sur les informations reçues en mai 2018 au travers de Windows 10, et des applications mobiles Facebook et Google. Ce choix est lié au fait que c’est principalement via ces modes de consultation respectifs que l’utilisateur y est confronté.
On l’a déjà dit, et observé pour la plupart d’entre nous, la meilleure façon d’ « orienter » un choix c’est de proposer un ensemble de cases pré-cochées. On informe succinctement, hein, mais sans plus. L’idée c’est que LaFlemme© va pousser les gens à laisser ça comme ça, parce que « faut lire » et « faut cliquer ». La nature étant basée sur un mode de fonctionnement allant vers l’économie d’énergie, et l’humain ne faisant pas exception à la règle, pourquoi ne pas exploiter ce biais ?
C’est tellement facile et efficace que l’UE a décidé, dans le RGPD, d’imposer un réglage par défaut réglé sur « préserver la vie privée ».
Et puisque ce mode n’est que difficilement compatible avec les activités de certains, toute la difficulté réside là : comment pousser gentiment l’utilisateur à modifier ce réglage par défaut, tout en lui donnant bonne conscience ?
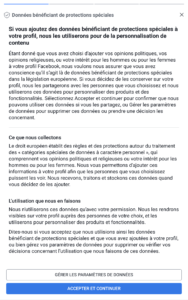
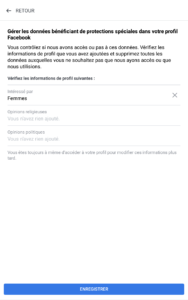
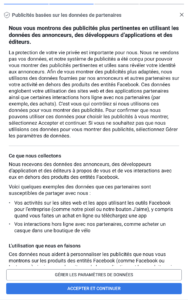
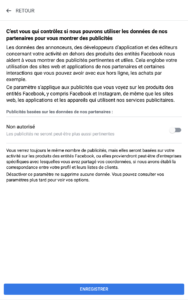
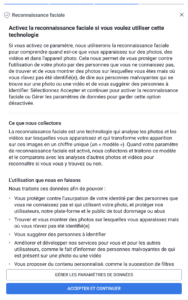
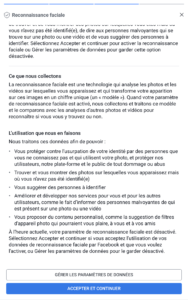
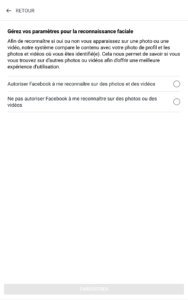
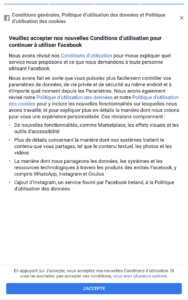
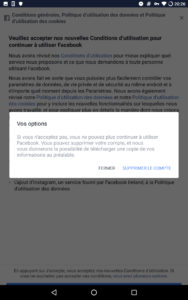
Les géants du net (mais sûrement pas qu’eux) ne s’y sont pas trompés : Google et Facebook proposent tous les deux des options par défaut qui ne sont pas celles qu’on attendait. Pour Facebook, d’ailleurs, on commence par un choix « Accepter et continuer » ou « Configuration avancée », en gros. Le truc qui fait peur et où personne ne va cliquer. On notera au passage que Facebook en profite pour réintroduire la reconnaissance faciale, désactivée depuis quelques années. Et côté Microsoft ? C’est bien géré : pas de choix par défaut, pour continuer l’utilisateur n’a d’autre choix que de choisir l’une ou l’autre des options présentées pour chaque fonctionnalité.
Graphiquement, on notera que pour Facebook, les cases « par défaut » (donc moins respectueuses de la vie privée) sont bleues, contrairement aux paramétrages « avancés », qui sont des cases grisées, moins engageantes.
Chez Google également, bien que l’écart soit moins flagrant, on observe la charte habituelle pour ce genre de formulaire : un bouton bleu, et un lien qui ressemble moins à un bouton. Je vous laisse deviner lequel correspond à quoi.
On notera au passage que le « parcours » chez Microsoft compte autant de clics dans tous les cas : pas de « raccourci » type « Tout accepter », de ce côté personne n’a cherché à dissuader l’utilisateur via un nombre de clics supérieur.
Côté formulation : vous connaissez le truc. On met des termes cool et positifs sur l’option qu’on veut voir choisie, et sur le reste on met du négatif, en insistant sur le fait que ça peut priver de certaines fonctionnalités, voire nuire à la qualité de service (quand bien même c’est faux).
Ainsi, on pourra lire chez Facebook que si on désactive la reconnaissance faciale, Facebook ne pourra pas nous prévenir si un autre profil utilise une photo de nous, potentiellement dans un cadre d’usurpation d’identité. C’est un argument recevable, en soi. Simplement, la reconnaissance faciale ne sert pas qu’à cela, et Facebook ne dit pas tout à ce moment-là.
Chez nos amis Google, on observe le même mécanisme, et on apprend que désactiver la publicité ciblée n’est pas vraiment utile, puisque nous verrons toujours de la publicité, mais « moins utile ». (il y aurait donc de la publicité utile ?)
Idem chez Microsoft, ou la remontée d’informations « complètes » chez Microsoft est apparemment une fonction génialissime.
Un autre biais très bien connu : la balance récompense/punition. On préfère tous un chocolat-récompense plutôt qu’un coup de fouet. Bon OK pas tous, mais la majorité, dirons-nous. Bref. C’est toujours assez subjectif, la notion du bien/mal étant au choix de l’arbitre.
Ce biais peut très souvent s’observer en liberté dans son habitat naturel (les GAFAM) : c’est le « take it or leave it », vous acceptez les nouvelles conditions, ou bien voilà la procédure pour fermer votre compte. Qu’on trouvait ici chez Facebook, Twitter… une technique roublarde et ressemblant pour le moins à une prise d’otage. On l’appelle souvent le « take it or leave it ».
Chez Google, on voit le même type de mécanismes : désactiver la publicité ciblée empêche par la suite de masquer, bloquer certaines publicités, ou d’en couper le son sur YouTube.

Et pour terminer sur ce sujet : on remarquera que ces 3 acteurs ont fait le choix non pas d’une communication anticipée, ou par courriel, avec un délai pour choisir, tout ça. Non. Tout ça apparaît à un moment où l’utilisateur veut utiliser le service, et où il n’a pas forcément l’envie ou le temps de tout lire et de cliquer partout pendant 5 minutes. Tout en laissant assez d’éléments visibles pour motiver l’utilisateur : sur son interface web, Facebook laissait visible le nombre de notifications, par exemple.
Alors, que faire ?
Take it, or leave it ? Si dans l’absolu la réponse est évidente (cesser d’utiliser ces services), en pratique il reste délicat pour pas mal de personnes de quitter l’un ou l’autre (ou davantage) de ces écosystèmes dont le but n’est définitivement pas de nous rendre service. Reste à espérer voir émerger des alternatives sérieuses, et profiter du droit à la portabilité nouvellement introduit par le RGPD…
Pour ce qui est des pistes : je vous encourage à « auto-héberger » vos courriels loin de ces plate-formes (sans forcément galérer, pourquoi pas en achetant un nom de domaine chez Gandi, OVH…), à quitter les réseaux sociaux privateurs (et à migrer sur une alternative chouette comme Mastodon — les oubliettes, c’est la vie #CeuxQuiSaventSavent ), à utiliser les services de Framasoft (par exemple) pour remplacer ceux de Google, ou encore à tester une distribution GNU/Linux de votre choix (pourquoi pas Linux Mint, très simple d’usage ?) en remplacement de Microsoft Windows. C’est un début.
On reparlera évidemment de tout ça par la suite ! 😉
Et pour mémoire : voilà les nombreux écrans de l’appli Facebook, pour lesquels j’avais déjà décoché les choses problématiques (désolé) :